Place a limit buy on Binance: the field is quantity. Do the same on OKX: it's sz. On Hyperliquid: it's s, the asset is an integer instead of a symbol, and the side is a boolean. Three exchanges, three completely different wire formats for the same operation — exchange connectivity is making your system speak all of them.
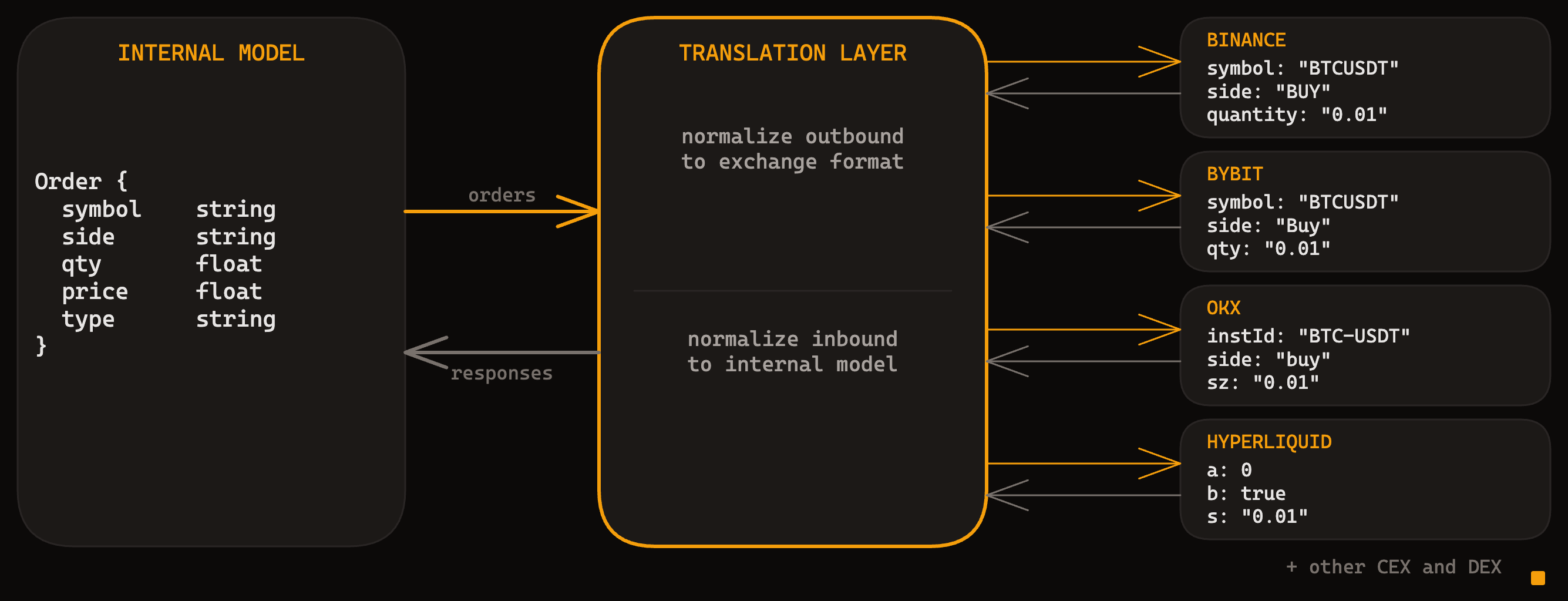 One internal model, four exchange dialects. The translation layer handles both directions.
One internal model, four exchange dialects. The translation layer handles both directions.
The common interface problem
Your internal trading system has one Order type. One Trade type. One set of assumptions about what a fill looks like and how errors are signaled. Every exchange violates at least some of those assumptions.
You're building a translation layer. Your system speaks one language. Each exchange speaks its own. The layer sits between them, converting outbound orders into whatever the exchange expects and converting inbound responses into your internal models.
CCXT is the open-source reference for this. It wraps 100+ exchange APIs behind a unified interface (createOrder, fetchTrades, fetchBalance) with standardized response objects. A CCXT Order always has the same fields: id, symbol, side, price, amount, filled, remaining, status. Regardless of which exchange it came from.
Good starting point. At production scale, you'll hit edges where exchanges don't behave the way the unified interface promises. CCXT handles this with an escape hatch: every unified object carries an info field containing the raw exchange response.
Production systems end up reaching into info constantly. Self-trade prevention modes, position sides, margin types. Fields the abstraction doesn't surface. The abstraction leaks by design, because it has to.
Outbound: your orders to the exchange
The same limit buy order, across four exchanges:
| Field | Binance | Bybit (v5) | OKX (v5) | Hyperliquid |
|---|---|---|---|---|
| Base URL | api.binance.com |
api.bybit.com |
www.okx.com |
api.hyperliquid.xyz |
| Endpoint | POST /api/v3/order |
POST /v5/order/create |
POST /api/v5/trade/order |
POST /exchange |
| Symbol | symbol: BTCUSDT |
symbol: BTCUSDT |
instId: BTC-USDT |
a: 0 (integer index) |
| Side | side: BUY |
side: Buy |
side: buy |
b: true |
| Quantity | quantity |
qty |
sz |
s |
| Price | price |
price |
px |
p |
| Order type | type |
orderType |
ordType |
t (nested object) |
| Client ID | newClientOrderId |
orderLinkId |
clOrdId |
c |
Same operation. Different field names, different casing (BUY vs Buy vs buy vs true), different symbol formats, different structural choices. Hyperliquid doesn't even use string identifiers for assets. You call the meta endpoint first to build a lookup table mapping integer indices to symbols.
The differences go deeper than naming. Time-in-force — whether an order should persist or cancel if not filled immediately — is a dedicated timeInForce parameter on Binance and Bybit: GTC, IOC, FOK. OKX encodes it in the order type field itself, ordType: "ioc" instead of a separate TIF param. Hyperliquid nests it inside a type object: {"limit": {"tif": "Ioc"}}.
Authentication differs. Binance, Bybit, and OKX use API key pairs with HMAC signatures, each constructing the signature string differently. Hyperliquid uses EIP-712 wallet signing. Agent wallets can trade on behalf of a master account, but the mechanism is cryptographic signing, not a shared secret.
Your normalizer maps the same concept across entirely different fields and structures. Not just different values for the same field.
Not every exchange supports every operation the same way. Bybit and OKX have long supported amending an order in-place, changing the price or quantity of a live order atomically. Binance added amend more recently, but it only supports reducing quantity while keeping queue priority — for price changes, you still cancel and re-place, which creates a window where you have no order on the book.
Batch order placement isn't universal. Some exchanges have a fetchTrade endpoint, others only have fetchTrades. CCXT tracks this with a has property on each exchange: true, false, or 'emulated' (meaning CCXT synthesizes the result client-side from other calls). Emulated methods work, but they're slower and may behave differently from a native implementation.
Your common interface has to handle "this exchange doesn't support that" as a first-class concept.
Inbound: exchange responses to your models
Outbound is messy. Inbound is worse.
Binance can return fill details inline — price, quantity, commission per fill, plus a transactTime — but only when newOrderRespType is FULL. Do the same on Bybit or OKX and you get an acknowledgment with your order ID but no fill details. Fills come later, through polling or a WebSocket subscription. Your code path for processing a fill differs per exchange.
Hyperliquid has its own thing going on. The response status is "ok" even when the order fails. The actual result (resting, filled, or error) is inside a nested statuses array. If your error handling checks the top-level status field, you'll miss order-level failures entirely.
Timestamps are another normalization problem. All four exchanges use Unix milliseconds, which sounds consistent until you realize OKX returns them as strings, not integers. In Go, your int64 field won't unmarshal from a JSON string without a custom decoder. You find out the hard way.
Server timestamps matter for latency measurement. Binance gives you transactTime. Bybit includes a time field at the top level. OKX and Hyperliquid don't include one at all.
Without a server timestamp, you can measure round-trip but you can't separate network latency from exchange processing time.
Every exchange paginates historical data differently. Binance uses ID-based cursors, pass the last fromId to get the next page. Bybit returns opaque cursor strings you pass back verbatim. OKX uses order IDs with after and before parameters, where after confusingly means "older than" and before means "newer than."
Default page sizes range from 20 on Bybit to 2,000 on Hyperliquid. Your normalizer needs separate pagination state machines per exchange. A simple offset-and-limit interface won't cut it.
Spot as the foundation
Everything above describes spot trading. Buying and selling assets, settled immediately.
Perpetual futures add funding rates, margin, leverage, position tracking, liquidation. The connectivity pattern is the same. You still map order types, normalize responses, handle pagination. On most exchanges, spot and perps share the same API, differentiated by a parameter.
Bybit uses a category field. OKX infers it from the instrument ID format. Hyperliquid uses asset index ranges (0 to 9,999 for perps, 10,000+ for spot). Binance is the exception: spot, USDT-margined futures, and coin-margined futures each have separate base URLs, separate authentication, and slightly different response schemas.
Build the translation layer for spot, extend it for derivatives. The plumbing is the same. Product-specific logic layers on top.
The maintenance burden
You don't build exchange connectivity once and walk away.
When an exchange lists a new trading pair, your system doesn't know about it until you re-fetch the symbol metadata. If you're trying to trade a new listing at launch, the first minutes matter. Your system needs to pick it up fast, and a stale symbol table costs you.
Exchanges update their APIs. New fields appear, field names change, response structures shift. Your code doesn't crash. It just silently misses new fields or misparses changed ones.
A response format change that adds an optional field won't throw an error. It'll be absent from your internal model until someone notices the data gap. You're maintaining connectors against a moving target.
CCXT absorbs some of this. It's open-source and community-maintained, so API changes get patched upstream. But some exchanges don't work as expected out of the box, and overriding CCXT for a specific quirk means understanding its internal dispatch — how unified calls map to exchange-specific ones. At production scale, teams often end up maintaining their own patches or writing direct integrations.
What this doesn't cover
Orders flow out in each exchange's dialect. Responses flow back, normalized. The translation layer works. Now what?
Rate limits that differ by exchange, by endpoint — some counting by weight, others by raw request count, some scoped to your API key, others to your IP. WebSocket feeds that drop while your subscription state drifts. Tens of thousands of trades a day where every fill needs to be confirmed and reconciled within seconds.
Keeping it running under real conditions is a different problem.
Part 1 of a series on exchange connectivity. Next: rate limits, error handling, and what changes when you move beyond spot.